Ce qu'il faut retenir
- TurboQuant compresse la mémoire de travail des LLM (key-value cache) par un facteur 6, sans perte de qualité mesurable
- L'algorithme combine deux techniques : PolarQuant (changement de coordonnées) et QJL (correction d'erreur à 1 bit)
- Sur GPU NVIDIA H100, la version 4 bits offre un speedup de 8x par rapport à la version non compressée
- Impact concret : réduction des coûts d'inférence, contextes plus longs, et déploiement sur des appareils à ressources limitées
- Applicable aussi à la recherche vectorielle (RAG, recherche sémantique)
Pourquoi les LLM consomment autant de mémoire
Pour comprendre TurboQuant, il faut d'abord comprendre le problème qu'il résout.
Quand un modèle de langage (GPT-4, Gemini, Claude, Llama 3, Mistral...) traite un texte long, il doit se souvenir de tout ce qu'il a lu. Pour cela, il utilise un mécanisme appelé key-value cache (cache clé-valeur) : une sorte de mémoire de travail à court terme qui stocke des représentations numériques de chaque mot ou concept rencontré.
Le problème ? Cette mémoire explose avec la longueur du texte. Un modèle comme Llama-3.1 8B qui traite un document de 100 000 tokens peut facilement consommer plusieurs dizaines de gigaoctets rien que pour son cache. C'est un goulot d'étranglement majeur : il limite le nombre de requêtes qu'un serveur peut traiter simultanément, augmente les coûts d'infrastructure IA et freine le déploiement sur des appareils à ressources limitées.
C'est là qu'intervient la quantization (quantification) : réduire la précision des nombres stockés pour diminuer la taille de cette mémoire.
La quantification des modèles IA, c'est quoi exactement ?
Imaginez que vous mesuriez la taille de chaque personne dans une pièce avec une précision au micromètre. C'est très précis, mais chaque mesure prend beaucoup de place à stocker. Maintenant, imaginez que vous arrondissiez au centimètre près : vous perdez un tout petit peu de précision, mais vous divisez drastiquement l'espace de stockage.
C'est exactement ce que fait la quantification numérique. Un nombre stocké en 32 bits (précision complète) est converti en 4 bits, 3 bits, voire 1 bit. À 4 bits, vous divisez déjà la mémoire par 8.
Pourquoi les méthodes classiques de compression IA atteignent leurs limites
Le problème, c'est que les méthodes de quantification traditionnelles doivent stocker des constantes de calibration — des paramètres supplémentaires qui permettent de "décoder" les nombres compressés. Ces constantes ajoutent 1 à 2 bits supplémentaires par nombre, ce qui réduit considérablement le gain de compression. C'est un peu comme si, pour compresser un fichier, vous deviez joindre un mode d'emploi presque aussi volumineux que le fichier lui-même.
Comment fonctionne TurboQuant, l'algorithme de Google
Google Research vient de publier TurboQuant, un algorithme qui résout élégamment ce problème de surcoût mémoire. Il sera présenté à la conférence ICLR 2026 (l'une des plus prestigieuses en apprentissage automatique).
TurboQuant fonctionne en deux étapes complémentaires :
Étape 1 : PolarQuant — changer de perspective mathématique
La première innovation est un changement de représentation mathématique. Au lieu de stocker les vecteurs dans un système de coordonnées classique (X, Y, Z), PolarQuant les convertit en coordonnées polaires : une direction (angle) et une intensité (rayon).
Pour prendre une analogie : au lieu de dire "avancez de 3 blocs vers l'est et 4 blocs vers le nord", vous dites "avancez de 5 blocs à 37 degrés". Les deux descriptions sont équivalentes, mais la seconde se compresse beaucoup mieux car les angles suivent des distributions prévisibles.
Ce changement de perspective élimine le besoin de stocker des constantes de calibration coûteuses. C'est la clé du gain de TurboQuant.
Étape 2 : QJL — corriger les erreurs de compression avec 1 seul bit
La seconde étape utilise l'algorithme QJL (Quantized Johnson-Lindenstrauss) pour corriger l'erreur résiduelle laissée par PolarQuant. QJL réduit chaque valeur à un seul bit (+1 ou -1) tout en préservant les distances entre les vecteurs. Il agit comme un correcteur mathématique qui élimine les biais de la première compression, avec un coût mémoire quasi nul.
Benchmarks : compression x6 sans perte de qualité
Les benchmarks publiés par Google sont remarquables.
Performance sur les tâches de compréhension longue
TurboQuant a été évalué sur le benchmark LongBench (qui teste la compréhension de textes longs) avec le modèle Llama-3.1-8B :
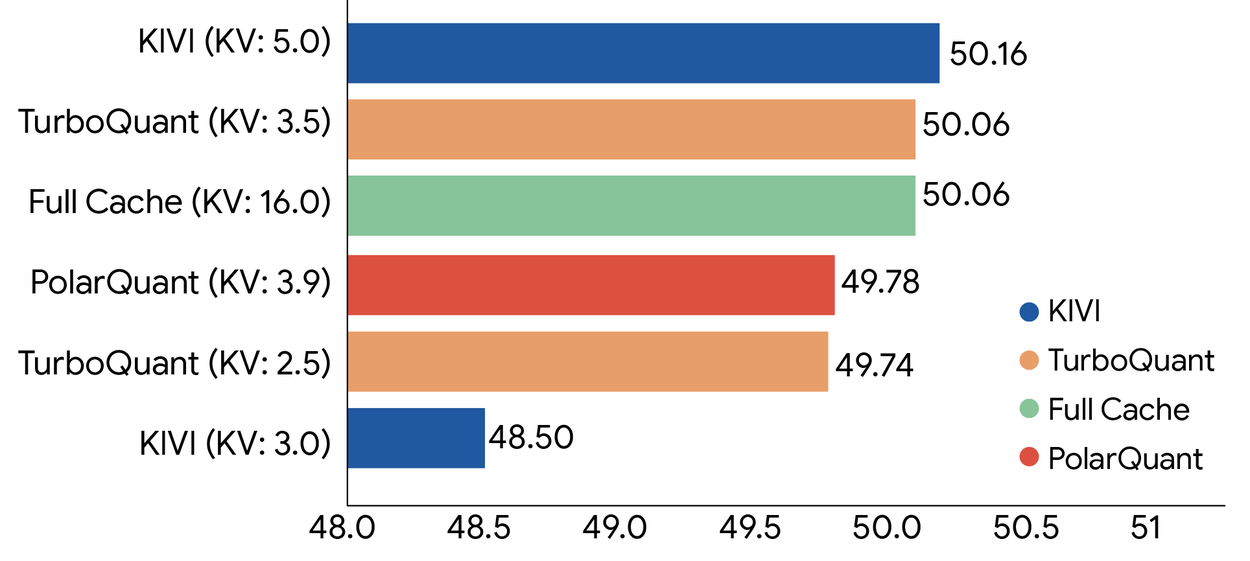
Les résultats montrent que TurboQuant maintient des scores quasi identiques au modèle non compressé, tout en réduisant la mémoire du cache clé-valeur par un facteur 6 ou plus. Sur les tâches "needle-in-a-haystack" (retrouver une information précise dans un texte massif), TurboQuant atteint des résultats parfaits — un test particulièrement exigeant.
Quel gain de vitesse pour l'inférence IA ?
Au-delà de la compression, TurboQuant accélère aussi le calcul. Sur des GPU NVIDIA H100, la version 4 bits atteint un speedup de 8x par rapport à la version 32 bits non compressée :
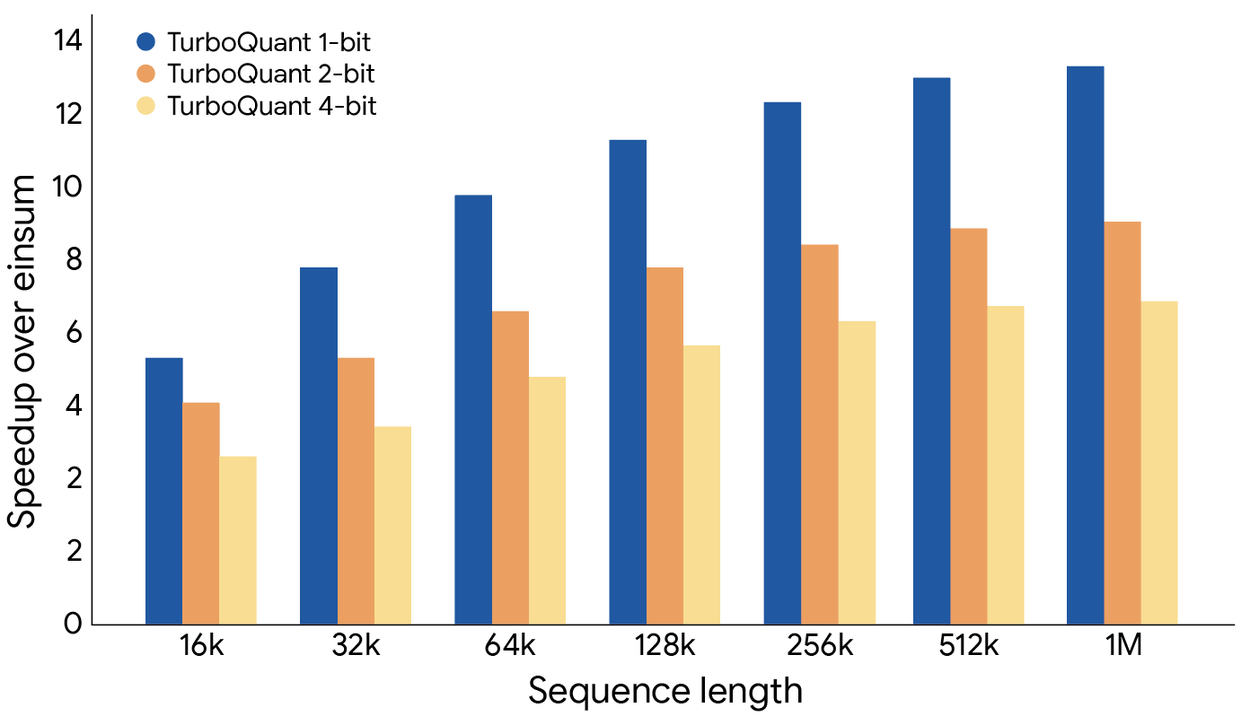
Moins de mémoire signifie aussi moins de transferts de données entre la mémoire et le processeur — d'où le gain de vitesse.
Application à la recherche vectorielle et au RAG
TurboQuant n'est pas limité aux LLM. Il s'applique aussi à la recherche vectorielle, la technologie qui permet de trouver des éléments similaires dans de gigantesques bases de données. C'est ce qui fait fonctionner la recherche sémantique, les systèmes de recommandation, et les architectures RAG (Retrieval-Augmented Generation) que nous déployons chez nos clients.
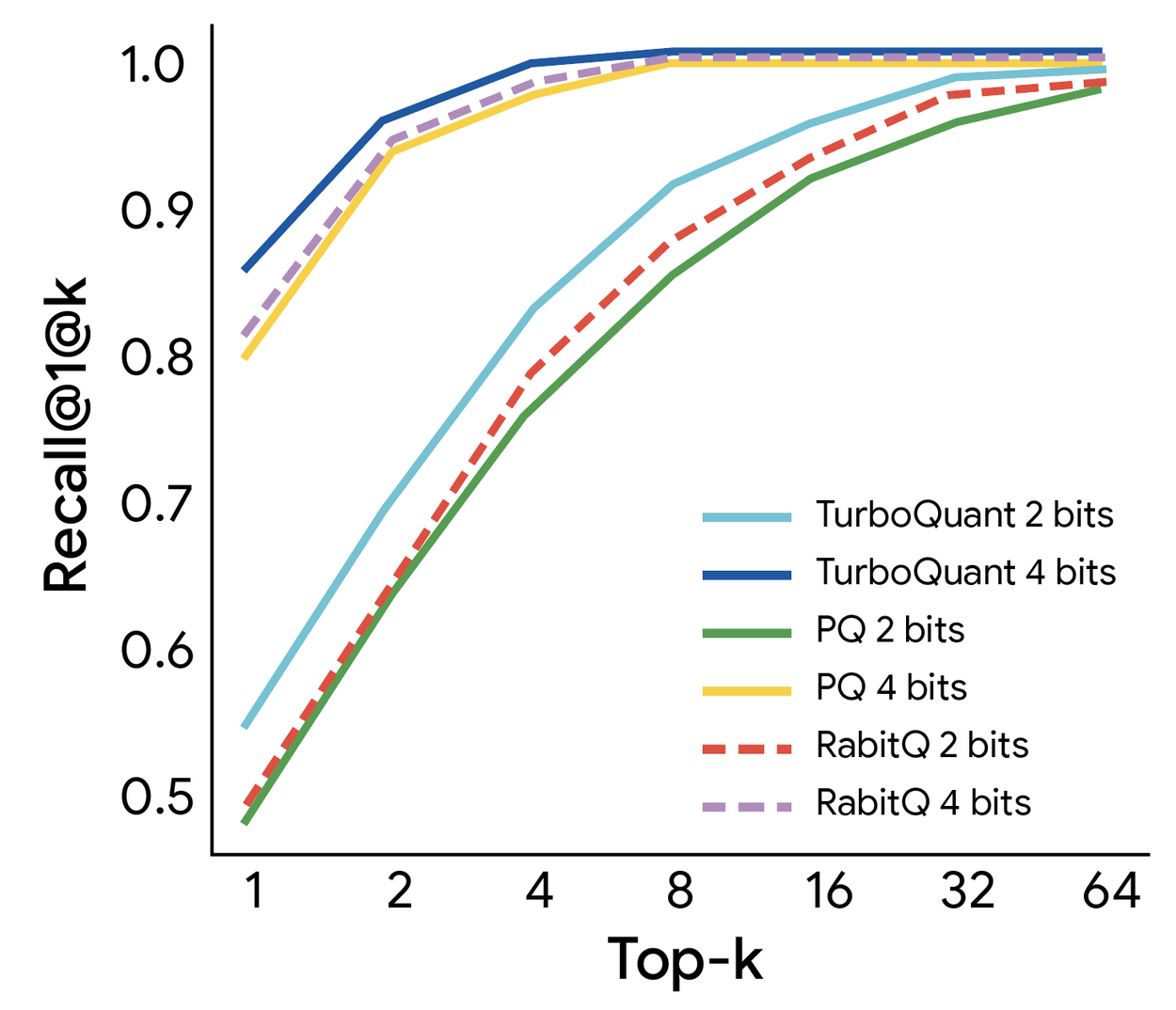
Sur le dataset GloVe, TurboQuant surpasse les méthodes existantes (Product Quantization, RabbiQ) en termes de taux de rappel, et ce sans nécessiter de calibration spécifique au dataset.
Quel impact concret pour les entreprises qui utilisent l'IA ?
Réduction des coûts d'inférence
- Diviser la mémoire par 6 signifie traiter 6 fois plus de requêtes sur le même matériel, ou utiliser du matériel moins cher
- Contextes plus longs : moins de mémoire consommée par le cache = plus de place pour des documents volumineux
- Déploiement embarqué : un modèle qui tient dans 3 bits de cache peut tourner sur des appareils mobiles ou des systèmes embarqués
Baisse structurelle des coûts de l'IA
- Prix des API en baisse : si les coûts d'inférence diminuent chez les fournisseurs, les prix suivront — un accélérateur pour les entreprises qui intègrent l'IA dans leurs processus
- IA locale et souveraine : des modèles plus compacts ouvrent la voie à l'exécution locale, sans envoi de données vers le cloud — un argument fort pour les organisations soumises à des contraintes de confidentialité
- Recherche sémantique plus rapide : les bases vectorielles (Pinecone, Weaviate, Qdrant) pourraient intégrer ces techniques pour des recherches plus rapides et moins coûteuses
Des fondations théoriques solides
TurboQuant n'est pas qu'une astuce d'ingénierie. Les auteurs fournissent des preuves théoriques que leurs algorithmes opèrent près des limites théoriques optimales de compression. C'est ce qui rend ces résultats robustes : ils ne dépendent pas d'un dataset ou d'un modèle spécifique.
Les limites à garder en tête
- Résultats de Google, sur des modèles Google : les benchmarks utilisent principalement Gemma et Llama. L'efficacité sur d'autres architectures (Mamba, architectures hybrides) reste à vérifier
- Pas encore en production : TurboQuant est une publication de recherche. Son intégration dans les produits Google (Gemini, Cloud) n'est pas annoncée
- Compression du cache, pas du modèle : TurboQuant compresse le key-value cache à l'inférence, pas les poids du modèle lui-même. Ce sont deux problèmes différents (même si PolarQuant pourrait être étendu aux poids)
- Concurrence active : d'autres approches existent (KIVI, KVQuant, Gear) et le domaine évolue vite
Conclusion : vers une IA plus efficace et moins coûteuse
TurboQuant illustre une tendance de fond : l'avenir de l'IA ne passe pas uniquement par des modèles plus gros, mais aussi par des modèles plus efficaces. Compresser le cache clé-valeur par 6x sans perte de qualité, c'est potentiellement diviser par 6 le coût d'exécution d'un LLM — un levier économique considérable.
Pour les entreprises qui déploient de l'IA à grande échelle, c'est une avancée à suivre de près. Pas pour l'intégrer immédiatement, mais parce qu'elle annonce une baisse structurelle des coûts d'inférence qui bénéficiera à tout l'écosystème dans les mois à venir.
Lire aussi : Voxtral TTS : Mistral entre dans la course au text-to-speech
Vous déployez des LLM en production et les coûts d'inférence sont un sujet ? Vous cherchez à définir la bonne architecture IA pour votre cas d'usage ? Parlons-en — nous accompagnons les entreprises dans leur stratégie IA, du cadrage au déploiement.