Ce qu'il faut retenir
- Voxtral TTS est le premier modèle text-to-speech de Mistral AI : 4 milliards de paramètres, 9 langues, latence de 70 ms
- Il permet de cloner une voix à partir de 3 secondes d'enregistrement et de piloter l'émotion (neutre, enthousiaste, sarcastique)
- Performances supérieures à ElevenLabs v2.5 Flash en naturalité, à parité avec ElevenLabs v3 en qualité
- Disponible via API à 0,016 $/1 000 caractères et en open weights sur Hugging Face (licence non-commerciale)
- Combiné avec Voxtral Transcribe, il forme un pipeline speech-to-speech complet entièrement européen
Pourquoi Mistral se lance dans la synthèse vocale IA
Jusqu'ici, Mistral AI s'était concentré sur les modèles de langage texte (Mistral, Mixtral, Ministral) et la transcription audio (Voxtral Transcribe). Avec Voxtral TTS, l'entreprise française complète la boucle : entrée audio, raisonnement texte, sortie vocale. C'est une pièce manquante qui permet désormais de construire des pipelines speech-to-speech entièrement sur la stack Mistral.
L'enjeu est clair : les agents vocaux sont en train de devenir l'interface dominante pour le support client, les services financiers, la santé et les objets connectés. Détenir un modèle TTS compétitif, c'est contrôler le dernier maillon de la chaîne conversationnelle IA.
Architecture technique de Voxtral TTS
Le modèle repose sur trois composants :
- Un backbone transformer de 3,4 milliards de paramètres, dérivé de Ministral 3B, qui assure la compréhension contextuelle du texte
- Un transformer acoustique flow-matching de 390 millions de paramètres, qui génère les latents audio en 16 étapes
- Un codec audio neuronal de 300 millions de paramètres, qui convertit les latents en signal audio à 12,5 Hz
L'ensemble pèse environ 4 milliards de paramètres — un modèle volontairement compact pour favoriser la vitesse et le coût de déploiement.
Performances clés du modèle
- Latence modèle : 70 ms pour un échantillon de 10 secondes et 500 caractères
- Facteur temps réel : environ 9,7x (le modèle génère l'audio 9,7 fois plus vite que la durée réelle)
- Langues supportées : 9 (anglais, français, allemand, espagnol, néerlandais, portugais, italien, hindi, arabe)
- Adaptation vocale : à partir de 3 secondes de référence seulement
Clonage vocal et expressivité émotionnelle
Le point fort revendiqué par Mistral est la capacité du modèle à capturer non seulement le timbre d'une voix, mais aussi ses nuances : pauses naturelles, rythme, intonation, variations émotionnelles. Le modèle peut piloter l'émotion (neutre, enthousiaste, sarcastique, etc.) et s'adapter au registre (formel, conversationnel).
Mistral met aussi en avant une capacité de traduction speech-to-speech cross-lingue en zero-shot : un prompt vocal en français avec un texte en anglais produit un anglais avec accent français naturel. Un usage intéressant pour les systèmes de traduction vocale en cascade.
Voxtral TTS vs ElevenLabs : que disent les benchmarks ?
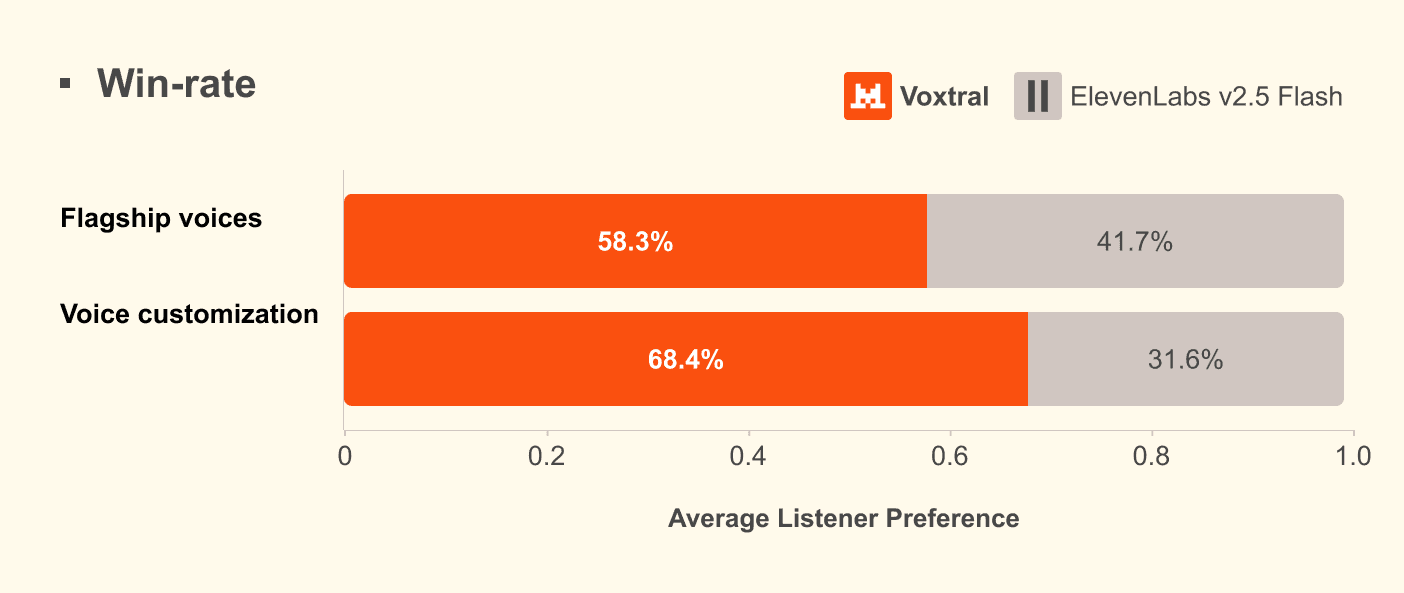
Mistral a mené une évaluation humaine comparative contre ElevenLabs v2.5 Flash et ElevenLabs v3 :
- Contre ElevenLabs v2.5 Flash : Voxtral TTS obtient une naturalité supérieure avec un temps de premier audio comparable. L'écart se creuse en contexte multilingue avec voix personnalisée en zero-shot
- Contre ElevenLabs v3 : performances à parité sur la qualité, avec un support équivalent du pilotage émotionnel
L'évaluation a été conduite par des locuteurs natifs sur 9 langues, avec 2 voix reconnaissables par langue et 3 annotateurs par paire. Le protocole teste la naturalité, la fidélité d'accent et la similarité acoustique à la voix de référence.
Ces résultats sont encourageants, mais il faut noter que l'évaluation est conduite par Mistral. Des benchmarks indépendants seront nécessaires pour confirmer ces performances.
Quels cas d'usage pour les agents vocaux en entreprise ?
Mistral positionne Voxtral TTS sur des workflows enterprise précis, que nous voyons aussi émerger chez nos clients lors de nos missions de conseil en IA :
- Support client : agents vocaux qui routent et résolvent les requêtes avec une voix naturelle alignée sur la marque
- Services financiers : vérification d'identité, résumés vocaux de transactions
- Industrie et logistique : instructions vocales pour les opérateurs terrain
- Services publics : accessibilité et interactions vocales multilingues
- Ventes et marketing : personnalisation vocale à grande échelle
Combiné avec Voxtral Transcribe pour la transcription entrante, l'ensemble forme un pipeline speech-to-speech complet sans dépendance à un fournisseur tiers.
Prix et disponibilité de Voxtral TTS
- API : disponible dès maintenant à 0,016 $ pour 1 000 caractères
- Playground : testable dans Mistral Studio et Le Chat
- Open weights : disponible sur Hugging Face sous licence CC BY-NC 4.0 (usage non-commercial)
- Webinaire : Mistral annonce un webinaire dédié sur la construction d'agents conversationnels avec Voxtral
La licence non-commerciale pour les poids ouverts est un point important : les entreprises souhaitant déployer en production devront passer par l'API payante.
Ce que cela change pour les entreprises françaises et européennes
Une alternative souveraine pour la voix IA
- Alternative européenne : Voxtral TTS offre une option souveraine face à ElevenLabs et aux solutions américaines, un argument de poids pour les entreprises soumises à des contraintes réglementaires (RGPD, données de santé, secteur public)
- Coût compétitif : le modèle compact de 4B paramètres permet un déploiement économique à grande échelle
- Stack unifiée : transcription + raisonnement + synthèse vocale chez un même fournisseur simplifie l'intégration et réduit les dépendances
Points de vigilance
- 9 langues seulement : suffisant pour l'Europe et les marchés principaux, mais limitant pour des déploiements globaux (pas de chinois, japonais, coréen)
- Licence NC pour l'open source : pas de self-hosting gratuit en production
- Benchmarks auto-produits : les résultats face à ElevenLabs demandent confirmation indépendante
- Écosystème jeune : ElevenLabs a plusieurs années d'avance en termes de communauté, d'intégrations et de retours terrain
Conclusion : le marché de la voix IA s'accélère
L'arrivée de Voxtral TTS confirme l'ambition de Mistral de devenir un fournisseur IA full-stack. Le positionnement est malin : un modèle compact, rapide, multilingue, qui s'intègre naturellement dans l'écosystème Mistral existant. Pour les entreprises qui construisent des agents vocaux, c'est une alternative crédible à considérer — particulièrement si la souveraineté des données ou l'intégration dans une stack Mistral existante sont des critères de choix.
Le marché du TTS IA s'intensifie. Après Cartesia Sonic 3 en octobre dernier, c'est au tour de Mistral d'entrer dans l'arène. La concurrence profite à tout le monde : les modèles s'améliorent, les prix baissent, et la voix IA se rapproche chaque jour un peu plus de la conversation humaine.
Lire aussi : TurboQuant : comment Google réduit les coûts d'inférence des LLM par 6
Vous explorez les agents vocaux IA pour votre entreprise ? Vous vous demandez quelle stack technique choisir entre Mistral, ElevenLabs, ou une solution on-premise ? Parlons-en — nous vous aidons à définir votre stratégie IA et à prototyper vos cas d'usage avant d'investir.




